
MW: Indicators: we don’t need to discuss these, to prove the Paris-Harrington theorem. But I think they offer valuable insight.
Let’s start with what an indicator indicates. Suppose N is a nonstandard model of PA, and we want to know if N has an initial segment I with some property P, that also “lies between” two given elements a and b. “Lies between” means that a∈I<b, and “I<b” means that b is a strict upper bound for I.
The intuition: the larger the “gap” between a and b, the more initial segments we have with a∈I<b. That makes it easier to find one enjoying property P. OK: let’s say a function Y(a,b) is an indicator for P, if Y(a,b) is nonstandard when and only when there exists an initial segment I with a∈I<b possessing property P. (Standing assumption: if b<a, then Y(a,b)=0. In mathspeak, by the way, if you possess something, you automatically enjoy it. Or at least this is true for mathematical objects.)
Example: Y(a,b)=b−a is an indicator for “is a cut”, i.e., is closed under successor. Clearly we have a cut I with a∈I<b if and only if a+n<b for all standard n.
(In keeping with the standing assumption, it’s implicit that Y(a,b)=0 when b<a; strictly speaking, the indicator is “if b<a then 0 else b−a”. This goes without saying in the future.)
Second example: Y(a,b)=⌊loga b⌋ is an indicator for “is an initial substructure”, i.e., is closed under plus and times, provided a>1. Clearly we have an initial substructure I with a∈I<b if and only if an<b for all standard n. In other words, iff ⌊loga b⌋≥n for all standard n. (To eliminate the proviso a>1, use Y(a,b)=⌊loga+2 b⌋ instead.)
So Y(a,b) measures the “size of the gap”. If Y(a,b) is highly “compressive”, then Y(a,b) being nonstandard indicates a “large” gap. Certainly ⌊loga b⌋ is more “compressive” than b−a.
Incidentally, people usually write Y(a,b)>ℕ to mean Y(a,b) is nonstandard.
BS: That is all very interesting, and understandable.
MW: ‘Well-behaved’ indicators (as Kaye calls them) obey some other conditions; we’ll talk about them later. Right now, to get a feel for the indicator concept, let’s temporarily set a=0, writing Y(b).
In this special case, Y(b)>ℕ means that “there’s room enough” below b, to fit an initial segment I with property P. Conversely, Y(b)∈ℕ means there isn’t enough room.
The growth rate of Y matters. If Y is slow-growing (like Y(b)=⌊log2 b⌋, compared to Y(b)=b), you’ll need to make b pretty big to get enough “headroom”. The slower Y grows, the bigger b needs to be.
BS: But isn’t ⌊log2 b⌋ nonstandard iff b is nonstandard?
MW: Oops! You’re right. Let me see where I went astray…
I wanted to emphasize, for now, how Y(a,b) depends on b. I forgot, though, that there’s always an initial segment I with 0∈I<b and with property P, for any nonstandard b and for the indicators we’ll be looking at. Namely ℕ! So Y(0,b) will be nonstandard for b>ℕ.
Let’s just assume a is some fixed value; I’ll write Y(b) sometimes for Y(a,b).
BS: Ok—so far, so good.
MW: How far out do you have to go for Y to “reach or crash through” a ceiling of height h? In other words, let’s define
F(a,h) = μb (Y(a,b)≥h),
sometimes writing just F(h). Here μb φ(b) stands for the least b such that φ(b) holds, and is undefined if there is no such b. (Standard notation in recursion theory.)
BS: So the slower Y grows, the faster the corresponding F grows?
MW: Right. Here’s a picture: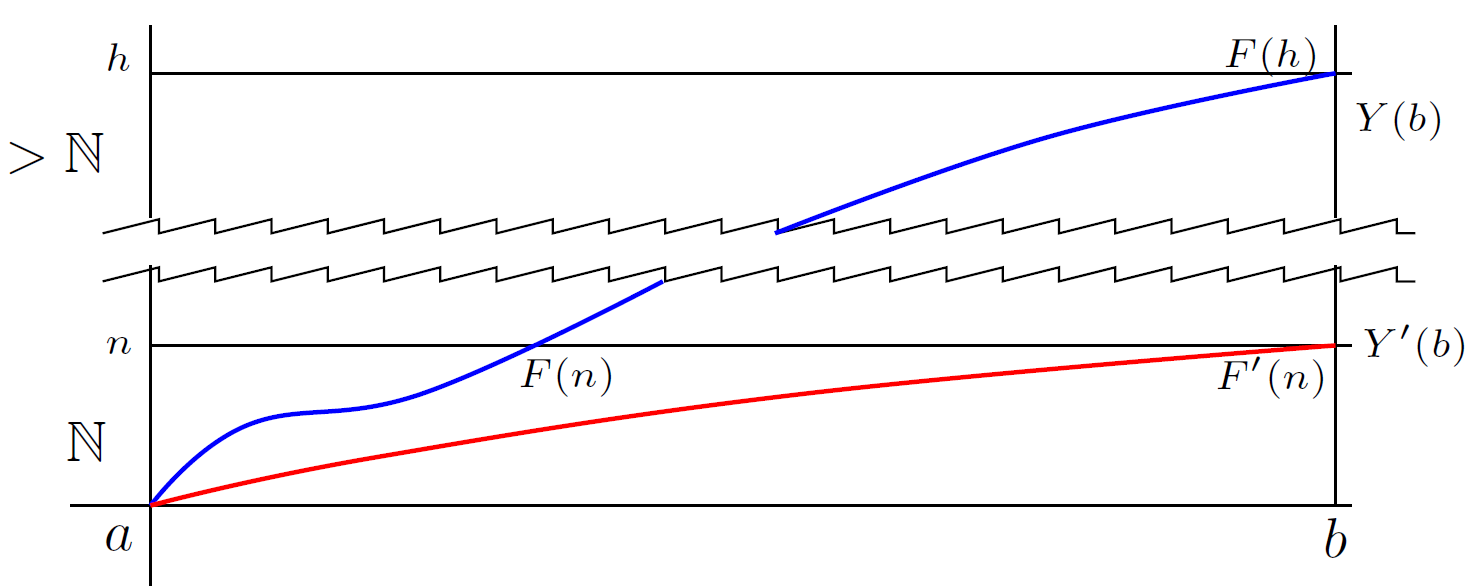
I’ve broken the vertical axis into the standard and nonstandard ranges. That’s because we’re asking “Is Y(b)>ℕ?” The horizontal axis goes from a to b, since Y(a,b)=0 for b<a (our standing assumption).
The blue indicator, Y, is faster-growing, while the red Y′ is slower-growing. As a result, Y(b)>ℕ while Y′(b)∈ℕ. For comparison’s sake, I’ve shown a ceiling at a standard height n.
BS: This is all understandable, but I’m not sure where you’re going with it…
MW: Let’s go through some examples of kinds of initial segments we might be interested in, and figure out how to define indicators for each one. How about an I which is a cut, but isn’t an initial substructure, so we can compare the indicators b−a and ⌊loga b⌋? Remember we want a∈I<b.
BS: I think we can just include every element up to a+n for arbitrary standard n. I.e., include all of a’s ℤ-copy and below. This is a cut, but not closed under either plus or times. I think this corresponds to Y(a,b)=b−a.
MW: Right. A little more formally, I is the downward closure of {a+n : n∈ℕ}.
BS: Let me see if I can come up with an initial segment closed under plus but not times, and containing a… I think we just want to include everything reachable by an for standard n. That is, the downward closure of {an : n∈ℕ}.
MW: Good. Can you think of an indicator for this property, “closed under plus”?
BS: Let’s see… I think ⌊b/a⌋ works. (I guessed this by following this pattern: if you want I to be closed under some operation, it only has to be closed under iterating that operation a standard number of times, and then the indicator can just compute that number of iterations, by inverting that operation. I’m not explaining this very clearly.)
MW: That’s right. Your explanation seems clear enough to me. So we have three indicators: b−a, ⌊b/a⌋, and ⌊loga b⌋. What are the corresponding F’s?
BS: F is just “solves for b” in Y(a,b) = h, so (ignoring the effects of inverting ⌊⌋): a+h, ah, ah. They look a lot more straightforward in that form!
MW: Yup. OK, now for the indicators we really care about. They’re for the property “is a model of PA”. Given the progression “a+h, ah, ah…”, we expect F(h) to grow even faster. I’ll talk more about that in a moment. But first, it’s time to list the conditions Kaye gives for a well-behaved indicator:
a. Y(a,b)=h is a Σ1 formula with only the free variables shown.
b. PA ⊢ ∀a∀b∃!h Y(a,b)=h.
c. PA ⊢ ∀a∀b Y(a,b)≤b.
d. PA ⊢ ∀a∀b∀c∀d (a≤b ∧ c≤d → Y(b,c)≤Y(a,d)).
(b) says that the formula for Y(a,b) defines a function. The notation makes this look inevitable, but if you wrote out ⌊logab⌋=h explicitly in L(PA), you’d have a pretty elaborate formula; proving (b) for it would take some doing.
BS: I understand. I suspect that could even be a Δ0 formula (not that I could personally construct it), but I know that before long, we’ll need the unbounded quantifier in Σ1 . But I’m willing to grant you that that will be sufficient for any function we’d consider computable (not that I can personally prove that, either).
MW: In ℕ, (a) implies that Y(a,b) is recursive. In a nonstandard model N, the meaning of ‘recursive’ gets a little fuzzy, so Kaye adopts (a) and (b) together as the definition of provably recursive.
BS: Don’t you need both Σ1 and Π1 (i.e. Δ1) for that, with Σ1 alone implying only r.e?
MW: For relations, that’s exactly right. But functions are special. ¬Y(a,b)=h is equivalent to ∃k(k≠h ∧ Y(a,b)=k), so if Y(a,b)=h is Σ1 then its negation is also Σ1. In other words, if Y(a,b)=h is Σ1, then it’s Δ1.
(c) is a technicality. Finally, (d) says that Y(a,b) gets bigger (or at least not smaller) if we move a to the left and b to the right. As a trivial consequence, Y(a,b) is monotonically increasing as a function of b when we hold a fixed. So our picture isn’t misleading.
If Y(b) is monotonically increasing, then F(h) = μb(Y(b)≥h) is strictly increasing (so far as it’s defined). Also we have (restoring the implicit argument a)
F(a,h)≤b ⇔ h≤Y(a,b).
BS: Ok, this is all making perfect sense.
MW: Here are two theorems about well-behaved indicators for “is a model of PA”:
- For each n∈ℕ, PA ⊢ ∀a∃!b F(a,n)=b.
- Not [ PA ⊢ ∀h∀a∃!b F(a,h)=b ].
Loosely speaking, F(a,h) increases so fast (as a function of h) that PA can’t prove it’s defined for all h. In ℕ, F is recursive but not provably recursive.
BS: Ok—it’s at least plausible to me that a property like that is very related to what you’d need to prove your cut I “extends far enough” to be a model of PA—since certainly it has to be closed under all provably recursive functions.
MW: Yes. That’s the key idea to proving (2). Or rather the contrapositive. If we can find a model of PA with elements a and h such that F(a,h) is undefined, then we can’t have PA⊢∀h∀a∃!bF(a,h)=b.
So suppose N is a nonstandard model of PA, and a is a nonstandard element of N. There’s one trick: use a for h. That is, we’ll look at F(a,a). It’s a diagonal argument!
If F(a,a) is undefined in N, we’re done. If not, let F(a,a)=b. Do you want to see if you can finish the argument?
BS: Let’s see: we have Y(a,b)≥a, because F(a,a)=b. But a is nonstandard, so Y(a,b) is nonstandard, so that is saying there is a cut I, which is a model of PA, which includes a and not b. Now, reasoning within that model I, F(a,a) is undefined, since b is not in that model. (I am assuming F is “sufficiently absolute” for this reasoning to work—since Y is Δ1, I am guessing so is F, since the same formula defines them, except for the technicality of which variable is the output which needs to be “rounded to an integer”.) Anyway, since F(a,a) is undefined in that model I, PA can’t prove it’s defined in every model, which completes the proof of (2).
MW: Good! Let’s look at the absoluteness issue. If we had F(a,a)=c for some c∈I, then we’d have Y(a,c)≥a for some c∈I. That’s inside I; that is, I⊧Y(a,c)≥a. But Y(a,c)≥a is a Σ1 formula (see below), and these are persistent upwards for end extensions. So we’d have N⊧Y(a,c)≥a with c∈I. Which means that b wouldn’t be the least x with N⊧Y(a,x)≥a, contradicting N⊧F(a,a)=b. So indeed, F(a,a) is undefined in I.
Y(a,c)≥a is shorthand for ∃h(Y(a,c)=h ∧ h≥a). And Y(a,c)=h is Σ1 (in fact Δ1, but we don’t need that here). So Y(a,c)≥a is Σ1.
BS: I notice I didn’t explicitly use conditions (c) or (d). Are they used in the technicality I glossed over, about how the formulas for F and Y are related?
MW: Well, (d) gave us the implication F(a,h)≤b ⇒ Y(a,b)≥h, which you used. I don’t think we’ll use (c) for anything, but I wanted to list all of Kaye’s conditions.
Now for the role indicators play in the Paris-Harrington theorem. The proof sketched in post 9 featured this setup, reprised at the end of post 21: a nonstandard model N of PA, and an initial submodel M, with the Paris-Harrington principle (PHP) holding in N but not in M. To state the PHP, we start with a combinatorial object sitting on top of an interval [a,b]. I’ll call the object a ‘colored hypergraph’, because that’s what it is, but we don’t need the details right now. We want to know if there’s a subset H of [a,b] of size h, with a certain property involving the colored hypergraph. The PHP says that for all a and h, there is b such that the desired H exists. In other words, just having b big enough will guarantee us the H. In fact, b will typically have to be much much bigger than a. So the PHP takes the form,
∀a∀h ∃b φ(a,b,h)
If F(a,h) = μb φ(a,b,h), then the PHP says that F(a,h) is well-defined for all a and h. Where there’s an F, there’s a Y: one can define a well-behaved indicator YPH for the PHP.
Here’s how the PHP shows up in the proof of the Paris-Harrington theorem. We need to find a nonstandard model where the PHP fails. Let N be a nonstandard model of PA. If N does not satisfy the PHP, then done. Otherwise, apply the PHP with a nonstandard h, getting an H of nonstandard size. Extract the set B of diagonal indiscernibles from this H. (How? Topic for later.) Define M as the downward closure of B, and we’re off to the races: the properties enjoyed by B ensure that M is a model of PA.
How do we show that M doesn’t satisfy the PHP? Well, both a and h turn out to belong to M, but b doesn’t. So you see it’s just like the proof of Theorem 2: F(a,h) is defined in N but not in M, and M is the initial submodel of N whose existence is guaranteed by the indicator.
BS: I see—that definitely helps motivate what we’ve been doing.
MW: We don’t need Theorem 1, but do you want to take a crack at it? I’ll start you off. By the completeness theorem, it’s enough to show that for all n∈ℕ and all models M of PA, M⊧∀a∃!bF(a,n)=b. Rephrase as an assertion about Y. Now we quote the MacDowell-Specker theorem: every model of PA has a proper elementary end extension, so let M⊂eN.
BS: Ok, let’s see. Rephrasing, M⊧∀a∃b(Y(a,b)≥n). Suppose for contradiction that, for some a we’ll hold fixed, there is no such b. Now you wouldn’t have mentioned N unless I should use it, but all I know about it is it has elements bigger than anything in M—and it has an initial segment M which is a model of PA. So pick an arbitrary c∈N\M, and consider Y(a,c). Since there is a model of PA containing a and not c, namely M, we better have Y(a,c) > ℕ.
Now let’s visualize the situation, to help find the contradiction. As a function of increasing x, Y(a,x) gets stuck at some maximal standard value (call it h) for an end-segment of M, but eventually reaches a nonstandard value for x = c. But consider the set of x for which Y(a,x) = h. That includes all elements of M from some point onwards. By overspill relative to the cut M, this set has to extend beyond the end of M, say to some d in N\M. But then Y(a,d) = h, which is standard, contradicting the existence of M as a model of PA between a and d (i.e., a∈M<d). QED.
(I guess I never did use c, only d. But I’ll leave it in, since it shows how I figured this out.)
MW: Very nice! I didn’t realize you could use overspill to prove this. The argument I had in mind is direct, and goes like this: since N⊧Y(a,c)≥n (because Y(a,c)>ℕ), N⊧∃x(Y(a,x)≥n). Now M is an elementary submodel of N, so M⊧∃x(Y(a,x)≥n), which is what we wanted to prove.
BS: That is indeed much more concise, and it uses the fact that N is an elementary extension—which I never used, or thought of trying to use. I need to get in the habit of paying more attention to that kind of assumption!
MW: Before we go, a couple more remarks. I’ve stated Theorems 1 and 2 for indicators for PA. Everything still works if you replace PA with an extension theory, say T. But if T is weaker than PA, no such luck. However, Kaye has versions of the theorems for any theory T in the language of arithmetic (§14.1). Things get considerably more complicated.
Wong’s Consistency notes (lecture 22) treat a special case with a weaker theory, the one known as IΔ0(exp). This allows for induction only over Δ0 predicates, and has additional axioms saying (basically) that exponentials exist and have the expected properties. Here, the function F is an iterated exponential. Wong uses this case as a paradigm for the Paris-Harrington Theorem. Very nicely done; well worth a look.
BS: Thanks, I will definitely check that out!
