TOC Next
This is the first in a series of posts, recording an e-conversation between John Baez (JB) and me (MW).
JB: I’ve lately been trying to learn about nonstandard models of Peano arithmetic. Do you know what a “recursively saturated” model is? They’re supposed to be important but I don’t get the idea yet.
MW: What books and/or papers are you reading? I used to know this stuff, indeed my thesis (1980) was on existentially complete models of arithmetic. When I looked at it a couple of years ago, I was amazed at how much I’d forgotten. Talk about depressing.
Anyway, I’ll toss out a few vague ideas, to see if they help. Maybe this will be the push I need to get back to Kaye’s book, or even Kossak & Schmerl. I picked them up a few months ago, hoping to revisit my youth, but I didn’t make it past the prefaces.
As Hodges puts it, model theory is “algebraic geometry minus fields”. If you have an algebraic number r in an extension field K/F, it’s natural to look at all the polynomials in F[x] which have r as a root. It turns out that this is a principal ideal, generated by the minimal polynomial.
Continue reading →

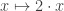 , for example, we write λx.(2·x). The λ-term ( λx.(2·x))7 stands for the application of the doubling function to 7, and we say that ( λx.(2·x))7 reduces to 2·7=14. (This is called β-reduction or β-conversion.)
, for example, we write λx.(2·x). The λ-term ( λx.(2·x))7 stands for the application of the doubling function to 7, and we say that ( λx.(2·x))7 reduces to 2·7=14. (This is called β-reduction or β-conversion.)