
I won’t define the (untyped) λ-calculus; you have the rest of the internet for that. But the basic formalism is remarkably simple. Instead of writing 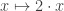
The λ-calculus gleefully flouts the notion that a function can’t be its own argument. For example, the identity function I is defined by λx.x, and II reduces to I. Try it: II written out is (λx.x)(λx.x). To β-reduce this, you take the right hand copy of (λx.x) and use it to replace the x in the left hand copy. (Maybe it’s easier if we rewrite II as (λx.x)I. This β-reduces to I.)
For my money, this is one of the most charming features of the λ-calculus. Of course, it does make it hard to model the λ-calculus via those earth-bound functions of conventional set theory. For the first few decades of its history, the untyped λ-calculus remained a computational formalism.
A λ-term is reduced if it can’t be reduced any further. So λx.x is reduced but (λx.x)(λx.x) isn’t. Not all λ-terms can be (fully) reduced. The self-application term provides the standard example: D = λx.xx. Now, D itself is reduced, but if we try to reduce DD, we end up in an infinite loop.
There is one natural model of the λ-calculus. Regard λ-terms as programs and not as functions. (Well of course!) Let Λ be the totality of all reduced λ-terms. With any reduced λ-term T, we associate the partial function from Λ to Λ that takes a reduced term W to the reduction of TW—that is, if it has a reduction. So you get a partial function.
It doesn’t seem like you could model the λ-calculus with total functions, but in the 1970s Dana Scott and Gordon Plotkin discovered (independently) that you can. I gave a seminar on a preprint by Scott. I recently latexed up my old hand-written notes; here’s the result.
I should say a word or two about the typed λ-calculus—everything above refers to the untyped calculus. Self-application is fun in some contexts, and sometimes very useful, but other times it’s a nightmare. To a computer scientist, having just one type for everything is the 9th circle of hell. After Scott came up with his model, he scaffolded up a whole theory of types based on these ideas. All very significant in theoretical computer science, but just a little too humdrum for my taste.

The typed λ-calculus doesn’t seem humdrum to me: this is the version that clearly reveals the connection to cartesian closed categories! This is the beginning of lots of fun.
“Types” are objects. The “untyped” λ-calculus should be called the “one-typed” λ-calculus, because it has just one type. While it’s bizarrely fun (and insanely dangerous) to have all data be of the same type when you’re doing computation, it’s sadly limiting and a bit mystifying from the category-theoretic point of view to focus on categories with just one object.
I recommend Lambek and Scott’s book for more on all this, or my lecture notes.
Huh. I ran out of categorical steam after I finished my Leinster solutions. That was just about when I was getting to Cartesian closed categories and topoi. I guess I’ll just have to add it to the list of 57 things I want to learn.
(The list is ever-renewing—it’s always 57 items long, no matter how much I learn. Kind of like the bowl in Greek mythology. Now if everyone else would just stop discovering new stuff…)
(Lately, I’ve been calling this my swid list.)